CPU
인간으로따지면 두뇌와 같은 부분입니다. 프로그램 명령어와 데이터를 읽어서 처리하고 명령어의 수행 순서를 제어합니다. CPU는 비교와 연산을 담당하는 산술논리연산장치(ALU)와 명령어의 해석과 실행을 담당하는 제어장치, 속도가 빠른 데이터 기억장소인 레지스터로 구성되어 있습니다.
- 데이터 버스
중앙처리장치와 다른 장치 사이에서 데이터를 전달하는 통로로 주소 버스, 제어 버스가 있습니다.
주소버스는 데이터를 정확하게 실어나르기 위한 주소를 전달하는 역할을 합니다.
제어버스는 CPU가 기억장치는 입출력장치에 제어 신호를 전달하는 통로입니다.(읽기 쓰기, 인터럽트 요청 승인, 클락 리셋 등)
캐시 메모리
CPU가 주기억장치에서 데이터를 읽어올 때, 자주 사용하는 데이터를 캐시 메모리에 저장한 뒤, 다음에 이용할 때 주기억장치가 아니라 캐시 메모리에서 먼저 가져옴으로써 속도를 향상시킵니다.
고정 소수점&부동 소수점
고정 소수점은 소수점이 찍힐 위치를 미리 정해놓고 표현하는 방식으로 정수부와 소수부로 나뉘어져 있습니다.
장점은 정수부와 소수부로 표현하여 단순하지만
단점은 표현의 범위가 정수부는 15비트 소수부는 16비트로 적기때문에 활용하기가 힘듭니다.
부동 소수점은 가수부와 지수부로 표현하는 방식입니다.
장점은 표현할 수 있는 수의 범위가 넓어집니다. 왜냐면 지수부는 $10-3$과 같이 간단하게 8비트 내로 표현이 가능하기 때문에 그만큼 가수부를 23비트로 넓은 범위로 표현할 수 있기 때문입니다.
단점은 가수부가 2진수로 표현될 때 무한소수가 되어 메모리를 초과하면 초과된 메모리가 날라가기 때문에 오차가 발생할 수 있습니다.
운영체제
일반적으로 하드웨어를 관리하고, 응용 프로그램과 하드웨어 사이에서 인터페이스 역할을 하며 시스템의 동작을 제어하는 시스템 소프트웨어입니다. 운영체제의 역할은 큰 틀로 프로세스 관리, 저장장치 관리, 네트워킹, 사용자 관리, 디바이스 드라이버 등의 역할을 하고 있습니다.
프로세스와 스레드
프로세스는 프로그램을 메모리 상에서 실행중인 작업을 의미합니다.
스레드는 프로세스 안에서 실행되는 여러 흐름의 단위입니다.

프로세스는 각각 별도의 주소공간 독립적으로 할당합니다.
Code 영역은 우리가 작성하는 소스코드가 들어가는 부분 즉, 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 부릅니다.
Data 영역은 전역변수 static변수, 배열 등의 초기화된 데이터를 저장하는 여역입니다.
Heap 영역은 동적 할당 시 사용하는 영역으로 대표적으로 new연산자가 있습니다.
Stack 영역은 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
하나의 프로세스가 생성될 때 최소 하나의 스레드가 같이 생성되고, 스레드는 stack을 따로 할당받습니다.
프로세스는 자신만의 고유 공간과 자원을 할당받아 사용하는데 비해,
스레드는 stack영역을 제외한 code, data, heap 영역의 자료들을 서로 공유합니다.
멀티프로세스
하나 이상의 프로세스를 병렬적으로 수행하는 방식으로, Context Switcing이라는 과정을 통해서 수행할 수 있습니다.
Context Switcing
CPU가 프로세스를 실행하기 위한 프로세스의 상태 정보를 Context라고 하며, 이 Context는 Process Controal Block(PCB)에 저장됩니다.
만약 두개의 프로세스가 있다고 가정했을 때, 프로세스1이 메모리에 올라와서 실행 중이다가 인터럽트가 발생하거나 입출력 요청이 발생하면 종료되고 PCB1에 Context를 저장합니다. 그리고 프로세스2의 Context가 메모라에 올라와서 CPU가 실행할 수 있도록 돕습니다.
하지만 PCB에 Context를 저장하고 가져올 때 CPU는 아무런 일도 못하고, 메모리와 레지스터 사이의 입출력이 자주 발생하기 때문에 성능이 저하될 수 있습니다.
멀티 스레드
하나의 응용 프로그램에서 여러 스레드를 구성해서 다수의 작업을 동시에 처리하도록 하는 것입니다.
스레드들은 메모리를 공유하고하고 있기 때문에, 자원 손실이 적습니다. 하지만 하나의 스레드가 데이터 공간을 망가뜨리면 모드 스레드가 작동 불능 상태를 갖는다는 단점이 있습니다.
인터럽트
프로그램을 실행하는 도중에 예기치 않은 문제가 발생하여 실행 중인 작업을 즉시 중단하고, 발생한 상황을 우선 처리한 후 실행 중인 작업으로 복귀하여 계속 처리하는 것을 의미합니다. 즉, 지금 수행하고 있는 작업보다 더 중요한 일이 발생하면 그 일을 먼저 처리하는 것을 의미합니다. 외부적으로는 외부 신호나 입출력 등 예를들어 프린트 요청과 같은 상황이 있습니다. 내부적으로는 잘못된 명령이나 데이터를 사용하연 Exception에 걸리는 경우가 있습니다.
프로그램 1 실행 -> 인터럽트 발생 -> 복귀주소 저장 -> 인터럽트 벡터로 점프 -> 인터럽트 처리 -> 인터럽트 처리 완료 -> 복귀주소 로드 -> 마지막에 실행되던 주소로 점프 -> 주 프로그램 실행
만약 인터럽트 방식이 없었다면 계속해서 상태변화를 체크해야하는 폴링 방식을 사용해야 한다. 따라서, 원래 수행하던 일에 집중을 하지 못하게 되어 많은 기능을 제대로 수행하지 못하게 됩니다.
스케쥴링
프로세스가 생성되어 실행되고 제거되기 까지의 주기를 관리하기 위한 방법입니다.
IPC(Inter Process Communication)
프로세스는 독립적으로 실행됩니다. 독립적으로 실행된다는 것은 프로세스들 서로가 영향을 주지 않는다는 의미입니다. 이런 독립적인 구조를 가진 프로세스들도 통신을 해야하는 상황이 생길 수 있습니다. 이를 가능하도록 해주는 것이 IPC통신입니다. 프로세스는 커널이 제공하는 IPC 설비를 이용해 프로세스간 통신을 할 수 있게 됩니다.
IPC 익명 PIPE와 Named PIPE, Message Queue, 공유메모리, 메모리 맵, 소켓 등이 있습니다.
익명 PIPE는 PIPE를 이용해서 하나의 프로세스는 읽기를 또 다른 하나의 프로세스는 쓰기가 가능합니다. 하지만 단방향으로만 통신이 가능하기 때문에 양방향으로 송/수신을 하기 위해서는 2개의 파이프를 만들어야 합니다.
Named PIPE는 익명PIPE에서 확장된 형태입니다. 익명 PIPE는 부모프로세스와 자식프로세스가 있을 때, 동일한 부모 프로세스를 가진 자식 프로세스 사이에서 통신이 가능하지만 Named PIPE는 부모 프로세스와 무관한 프로세스간에도 통신이 가능합니다.
Message Queue의 입출력 방식은 Named PIPE와 동일하게 선입선출 Queue방식으로 구성되어 있습니다. 하지만, Message Queue는 파이프와 같은 데이터의 흐름이 아니라 메모리 공간입니다. 사용할 데이터에 번호를 붙여서 여러 프로세스가 동시에 데이터를 쉽게 다룰 수 있습니다.
공유 메모리는 통신을 통해 데이터를 송/수신 하는 것이 아니라 데이터 자체를 공유하는 방식입니다. 스레드처럼 메모리를 공유한다면 통신과 같은 중개자 역할이 없이도 곧바로 메모리에 접근하여 빠르게 원하는 데이터를 얻고 쓸수 있을 것입니다. 공유 방식을 사용하기 때문에 내가 전달하는 데이터를 상대방이 명확하게 읽어하게 하기 위해서 동기식 기술이 필요하게 됩니다.(시스템 측면으론 좋지만 구현이 좀 어려움)
메시지 패싱은 두 프로세스 사이에 통신을 메시지 형태로 전달하고 전달받는 것을 의미합니다. 메시지를 전달하고 전달 받기 위해서는 메시지 채널을 거쳐야 하기 때문에 메시지 채널을 생성하는 과정 그리고 데이터를 메시지 채널에 복사하는 과정에서 오버헤드가 발생할 수 있습니다.(프로그래머한텐 간단함, 시스템 호출 Send() REcieve())
메모리 맵은 공유 메모리처럼 메모리를 공유한다는 측면에서는 동일하지만 데이터를 파일로 메모리에 매핑시켜서 공유한다는 점이 다릅니다. 파일은 시스템의 전역적인(모두 공유할 수 있는)자원이므로, 프로세스간의 공유가 가능합니다.
소켓은 네트워크 소켓 통신을 통해 데이터를 공유하는 방식입니다. 클라이언트와 서버가 소켓을 통해서 통신하는 구조로, 원경에서 프로세스 간 데이터를 공유할 때 사용합니다.
동기식 통신(Synchronous, Blocking)
두 프로세스 혹은 두 개체가 시간상으로 어떤 포인트를 일치시키는 것이 동기입니다. 예를 들어서, A 프로세스가 메시지를 Send를 시작하고 마치는 시간과, B프로세스가 메시지를 Receive하고 마치는 시간을 일치시키는 것이 동기식입니다. 하지만, 프로세스들은 스케줄링에 의해서 동시에 실행되는 것처럼 보일 뿐이지 사실은 동시에 실행이 되지 않기 때문에 A프로세스의 Send와 B프로세스의 Recevie가 동일한 시간에 Return되는건 불가능합니다. 따라서, 만약 A프로세스가 Send를 했다면 바로 Return되는 것이 아니고 B프로세스가 Receive할 때까지 기다렸다가 읽으면 그 때 함께 Return되는 것이 동기식입니다. Receive는 마찬가지로 커널의 메시지 전달 채널에 Send 메시지가 없다면 대기했다가 있다면 함께 Return하는 방식이 동기식입니다.
비동기식(Asynchronous, nonblocking)
두 프로세스 혹은 두 개체가 시간상으로 어떠한 포인트를 일치시키지 않는 것이 비동기식입니다. A프로세스가 Send를 전송했을 때, B프로세스가 Receive하지 않더라도 바로 다음 작업을 수행하는 것이 비 동기식입니다. 마찬가지로 B프로세스가 Receive를 하는데 커널의 메시지 채널에 Send 메시지가 없으면 Null을 바로 리턴해서 다음 작업을 수행하는 것입니다.(성능 적인 측면에서 blocking = 기다리는 과정이 없기 때문에 더 상승할 수 있지만 원하는 데이터를 얻지 못할 수 있다. 하지만 이 또한 상관 없다면 비동기식으로 한다)
랑데부
Send와 Receive가 모두 동기식이면 어떤 시점에서 만난다 시간상 포인트가 일치하게 된다는 의미입니다.
CPU 스케쥴링이 뭔가요?
운영체제의 CPU 스케쥴링은 다수의 프로세스가 준비 상태에 있을 때, CPU가 어떤 프로세스를 먼저 처리하도록 할 것인가를 결정하기 위한 정책을 의미합니다.
결과적으로, CPU 스케쥴링을 통해 얻고자 하는 목적은 즉, 좋은 CPU 스케줄링은 시스템관점과 프로세스 관점에서 생각해볼 수 있습니다.
시스템 관점에서는
1. CPU가 실제로 프로세스를 실행하고 있는 시간의 비율 즉, CPU가 놀고 있는 시간이 없도록 하는 것이 중요한 목적입니다
2. 그리고 특정 시간에 처리한 프로세스의 개수 즉 처리량이 많을 수록 좋은 CPU 스케줄링 알고리즘입니다.
프로세스 관점에서는
1. 실행되고 종료되기까지의 전체 시간이 짧을 수록 즉, 빠르게 처리될 수록 좋고
2. 한 프로세스가 Ready Queue에서 대기하는 시간이 적어야하며
3. 프로세스가 New상태에서부터 CPU를 할당받아 실행되기까지의 시간이 짧아야합니다.
이러한 스케줄링은 프로세스가 생성되고 종료되기까지 여러 상태들을 관리하고 전이시키는 역할을 하게 됩니다. 상태의 시작은 New 종료는 Running상태에는 프로세스가 실행중인 상태가 됩니다. 그리고 프로세스가 실행중인 Running상태, I/O나 이벤트 요청에 의한 Wait상태, 프로세스가 다시 선택되기를 기다리고 있는 Ready상태가 있습니다.
이와 같이 프로세스의 상태가 전이되는 과정에서 CPU는 어떤 프로세스를 언제 실행해야되고 어떤 프로세스를 언제 놓아주어야 하는지 결정을 해야하는데 이러한 경우에는 큰 맥락으로 봤을 때 선점 스케줄링 방식과 비선점 스케줄링 방식을 기반으로 수행하게 됩니다.
선점 스케줄링(Preemptive Scheduling)
(현재 Running중인 프로세스가 Interrupt에 의해서 CPU권한을 뺏겨서 새로운 프로세스에 CPU가 할당되어 Running되는 스케줄링 방식이 선점 스케줄링입니다.)
선점 스케줄링은 현재 CPU가 할당되어 Running중인 프로세스를 강제로 중단시켜서 새로운 프로세스에 CPU를 할당하는 방식입니다.
따라서, 특정 프로세스에 대해서 빠르게 응답하여 실행할 수 있다는 장점이 있지만 Context Swiching이 빈번해져서 오버헤드가 증가하게 된다는 단점이 있습니다. 일반적으로 Timer나 입출력 완료에 의해 인터럽트 발생시에 동작하게 됩니다.
1) Priority Scheduling (우선순위 스케줄링) = 기본정책
프로세스의 우선순위에 따라서 높은 우선순위부터 순서대로 처리하는 방식을 의미합니다. Shortest Job First가 우선순위 스케줄링의 특별한 예로도 볼 수 있는데, CPU Burst를 기준으로 우선순위를 측정할 수 있기 때문입니다. 우선순위 스케줄링은 Shortest Job First처럼 선점 혹은 비선점 스케줄링으로 구현을 할 수 있습니다.
- 특성 : 작은 우선순위의 프로세스들은 자신의 차례를 무한정 기다리게 될 수 있어서 Starvation이 발생할 수 있습니다(Aging으로 해결)
- Aging : 우선순위의 기준을 Ready Queue에서 대기 시간으로 잡아서 오래 대기하고 있는 프로세스의 우선순위를 점진적으로 증가시키는 방식입니다.
2) Round Robin(RR 라운드 로빈) = 기본정책
Time-Sharing 즉, 시분할 시스템(CPU의 시간을 쪼개서 프로세스에게 공평하게 나눠준다)의 스케줄링 알고리즘입니다. 각 프로세스들을 동일한 Time Quantum으로 처리하여 스케줄링을 수행함으로써, Running되고 있는 프로세스가 정해진 시간을 넘어가게되면 Timer Inturrupt를 걸어서 Ready Queue로 다시 들어가게됩니다. 즉, 강제적으로 프로세스의 CPU점유를 채가기 때문에 선점 스케줄링에 해당되는 알고리즘입니다.
- 특성 : SJF보다 응답 시간은 짧지만 Ready Queue에서 대기하는 시간은 더 길어질 수 있습니다.

- Quantum이 너무 짧으면 프로세스의 응답성이 빨라지지만 문맥교환이 잦아져서 오버헤드가 발생할 수 있다.
- Quantum이 너무 크면 FCFS스케줄링과 동일한 퍼포먼스를 보이게 된다.
- Rule of Thumb 즉, Time Quantum은 전체 CPU burst의 80%보다 커야한다라는 경험에 의한 법칙이 이미 정해져 있습니다.
3) Multilevel Queue(다단계 큐)
작업들을 여러 종류의 그룹으로 나누어서 여러 개의 큐를 이용하는 기법입니다. 우선순위가 높은 큐는 작은 Time Quantum을 할당하고 우선순위가 작은 큐는 큰 Time Quantum을 할당받게 됩니다. 따라서, 우선 순위가 높은 큐는 Round Robin 우선 순위가 낮은 큐는 FCFS를 사용하게 되는 것입니다. 예를 들어서, 사용자의 Foreground에서 빠르게 응답해줘야 하는 프로세스는 Round Robin 사용자의 Background에서 빠르게 응답하지 않아도 되는 프로세스는 FCFS를 사용할 수 있게 됩니다.
4) Multilevel Feedback Queue(다단계 피드백 큐)
다단계 큐는 프로세스의 특성에 따라서 다른 종류의 Ready Queue를 두어 선택하는 방식입니다. 하지만 예를 들어서 어떤 프로세스가 Foreground에서 빠른 응답을 원했다가 Background 동작으로 변경이 될 수도 있습니다. 이에 따라서 프로세스를 Ready Queue사이에서 이동이 가능하도록 하는 스케줄링이 다단계 피드백 큐입니다.
- 복잡한 스케줄링 알고리즘이지만 시스템에 가장 적합한 일반적인 알고리즘이며, 선점 스케줄링 방식이라는 특성이 있습니다.
비선점 스케줄링(NonPreemptive Scheduling)
비선점 스케줄링은 현재 CPU가 할당되어 Running중인 프로세스를 강제로 중단시키지 않고 스스로 중단되어 다른 프로세스가 CPU를 점유하여 Running되는 방식을 의미합니다. 어떤 프로세스가 File I/O나 Event를 요청하게 되면, CPU를 사용하지 않고 응답을 기다려야 하기 때문에 자발적으로 Waiting상태에 진입하게 되고 다른 프로세스가 CPU를 점유하게됩니다. 이처럼 자발적으로 CPU권한을 내려놓아야 하는 상황에서 비선점 스케줄링 방식을 사용할 수 있습니다.
1) FCFS(First Come First Served 선입 선처리)
선입 선처리는 Ready Queue에 들어있는 프로세스들은 First In First Out Queue 방식으로 처리해서 먼저 들어온 프로세스를 선택해서 Running시키는 방식을 의미합니다.
- 특성 : 평균 대기 시간이 길어진다는 단점이 생기고 Convoy 효과 즉, 여러 프로세스가 CPU를 얻기 위해 하나의 CPU Burst가 긴 프로세스를 기다려야하는 상황이 발생합니다.
2)SJF(Shortest Job First 최단 작업 우선) = 우선순위 스케쥴링의 특별한 예이기도 함
First Come First Served 방식과는 관계 없이 Ready Queue에서 대기중인 프로세스 중 CPU Burst 가장 짧은 프로세스부터 선택해서 Running시키는 방식을 의미합니다.
- 특성 : 평균 대기 시간이 매우 단축되는 최적의 알고리즘이 될 수 있지만 다음 CPU Burst를 예측해야 된다는 측면에서 실제 구현이 어렵습니다.
- 선점형 SJF를 사용하면 새로 Ready Queue에 도착한 프로세스의 CPU Burst가 실행중인 프로세스의 남은 CPU Burst 시간보다 작으면 선점해버림
데드락
Q. 데드락이 뭔가요? 발생 조건에 대해 말해보세요
- 만약, 프로세스1과 프로세스2가 자원1,2를 모두 필요로 한다고 가정하겠습니다. 그러면, 프로세스1이 자원1을 얻고 프로세스2가 자원2를 얻습니다. 그런데 프로세스1이 자원2를 얻으려면 프로세스2를 기다려야하고 프로세스2가 자원1을 얻으려면 프로세스1을 기다려야합니다. 즉 서로 원하는 자원이 상대방에게 할당되어 있어서 무한정 wait되는 상황을 데드락이라고 합니다.
발생조건 1) 상호 배제 : 자원은 한번에 한 프로세스만 사용할 수 있습니다
발생조건 2) 점유 대기 : 최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재해야 합니다.
발생조건 3) 비선점 : 이미 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 뺏을 수 없습니다.
발생조건 4) 순환 대기 : 프로세스의 집함에서 순환 형태로 자원을 대기하고 있어야 합니다.(cycle이 돌아야함 1:1도 마찬가지지)
Q.예방 방법이 뭔가요
교착 상태 발생 조건 중 하나를 제거하면서 해결합니다 하지만 심각한 자원 낭비로 이어질 수 있습니다.
1) 상호배제 부정 : 여러 프로세스가 공유 자원 사용
2) 점유대기 부정 : 프로세스 실행전 모든 자원을 할당
3) 비선점 부정 : 점유 중인 프로세스가 다른 자원을 요구할 때 강제로 뺏음
4) 순환대기 부정 : 자원에 고유번호를 할당 후 순서대로 자원 요구
Q.회피 방법은 무엇인가요 은행원 알고리즘으로 설명
은행에서 모든 고객의 요구가 충족되도로 현금을 할당하는데서 유래했습니다.
프로세스가 자원을 요구할 때, 시스템은 자원을 할당한 후에도 안정 상태로 남아있게 되는지 사전에 검사하여 교착 상태를 회피합니다
안정상태면 자원 할당, 아니면 다른 프로세스들이 자원 해지까지 대기합니다 참고 : jhnyang.tistory.com/102
Q기아상태를 설명하는 철학자 문제
원형 탁자에 철학자들이 앉아서 밥을 먹으려고 하는데, 왼쪽 포크를 짚고 오른쪽 포크를 짚어서 식사를 해야되는 상황에서 모든 철학자들이 왼쪽 포크를 짚는다면 오른쪽 포크를 짚지 못하여 모두가 식사를 못하는 데드락 상태가 발생합니다.
이를 해결하기 위해서는 포크를 n개 더 구매하거나, 짝수은 왼쪽포크부터 홀수는 오른쪽포크부터 들도록 조건을 추가하는 방식으로 해결할 수 있습니다.
Race Condition
다수의 프로세스나 스레드가 공유 자원에 접근함으로써 공유 자원의 일관성이 깨지는 상태 즉, 프로세스들의 경쟁 상황을 의미합니다.
만약 A스레드와 B스레드가 count라는 변수를 증가 또는 감소하는 코드가 있다고 가정해보겠습니다.
A 스레드
regA = count;
regA = regA + 1;
count = regA
B스레드
regB = count
regB = regB-1
count = regB
동기화가 배제된 위의 스레드들이 뒤섞여 실행된다면
regA = count (regA : 5)
regB = count (regB : 5)
regA = regA + 1 (regA : 6)
regB = regB - 1 (regB : 4)
count = regA (count : 6)
count = regB (count :4) 즉, count의 값이 4가 될 수도 있고 6이 될 수도 있다.
임계영역
따라서 임계영역을 지정하여 프로세스간의 공유자원을 접근하는데에 있어서 문제가 발생하지 않도록 한번에 하나의 프로세스만 이용하게끔 보장해야합니다.
임계 영역 문제(race condition)문제를 해결하기 위해서는 세가지 조건을 충족해야합니다.
1) 상호 배제 : 하나의 프로세스가 임계 영역에 들어가 있으면 다른 프로세스는 들어갈 수 없어야 한다.
2) 진행 : 임계 영역에 들어간 프로세스가 없는 상태에서 여러개의 프로세스가 임계 영역에 들어가면 어느 것이 먼저 들어갈지 결정해 주어야한다.
3) 한정 대기 : 다른 프로세스의 기아(starvation)을 방지하기 위해, 한 번 임계 구역에 들어간 프로세스는 다음 번 임계 영역에 들어갈 때 제한을 두어야 한다.
위 세가지 조건을 충족함으로써 임계 영역의 동시 접근 문제를 해결하는 방법은 아래와 같다.
Lock과 세마포어(Semaphore)와 뮤텍스(Mutex)
Lock은 하나의 스레드가 자원을 사용하고 있는 동안에는 잠궈서 접근을 못하게 하는 방식입니다.(상호 배제)
A스레드가 공유자원 Lock을 걸고 사용하고 있는 동안 라운드 로빈 스케줄링에 의해 Timer Interrupt가 결렸다고 가정하고 B 스레드가 수행되면 B스레드가 공유자원을 접근하려고 할 때 Lock이 해제되기를 기다리게 됩니다.(Busy-waits) 그리고 다시 A 스레드가 스케줄링에 의해 나머지를 다 수행하고 Lock을 해제하면 그제서야 B스레드가 수행되는 것이 Lock의 방식입니다.
Lock과 Mutex는 임계영역의 락이 풀릴때까지 기다려야 한다는 것은 같지만
Lock은 락이 걸려있을 경우 해제될때까지 무한 루프를 빠져나오지 못하게 하여 CPU를 양보하지 않습니다.
Mutex는 락이 걸려있을 경우 락이 풀릴때까지 기다리며 컨텍스트 스위칭을 실행합니다. 병렬적인 처리를 하기 위해 CPU를 양보할 수 있습니다. 하지만 단기간에 풀릴 경우에는 콘텍스트 스위칭에 의한 자원 낭비가 발생할 수 있습니다.
while(true) {
flag[i] = true; // 프로세스 i가 임계 구역 진입 시도
while(flag[j]) { // 프로세스 j가 현재 임계 구역에 있는지 확인
if(turn == j) { // j가 임계 구역 사용 중이면
flag[i] = false; // 프로세스 i 진입 취소
while(turn == j); // turn이 j에서 변경될 때까지 대기
flag[i] = true; // j turn이 끝나면 다시 진입 시도
}
}
}
// ------- 임계 구역 ---------
turn = j; // 임계 구역 사용 끝나면 turn을 넘김
flag[i] = false; // flag 값을 false로 바꿔 임계 구역 사용 완료를 알림
세마포어는 이진 세마포어와 카운팅 세마포어로 두 가지가 있습니다. 이진 세마포어는 상호배제를 이용한 프로세스 동기화로 뮤텍스와 같다고 볼 수 있습니다. 하지만 카운팅 세마포어는 여러개의 프로세스나 스레드가 동시에 최대 허용치까지 자원에 접근 가능합니다. 또한 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있습니다.
메모리
메모리는 데이터를 저장하는 저장장치인데 보조저장장치인 HDD나 SSD와는 달리 데이터를 읽고 쓰는 속도가 매우 빠르기 때문에 CPU가 직접적으로 접근할 수 있는 저장장치입니다. 그리고 컴퓨터의 전기가 끊어지면 데이터가 모두 사라지는 휘발성을 저장공간입니다
그래서 프로그램이 실행되기 위해서는 반드시 메모리에 프로그램에 대한 데이터들이 저장되어야 하고 CPU는 메모리의 주소를 가지고 데이터를 읽고 쓰게됩니다. 이 때, 메모리 관리라는 것은 프로세스가 필요한 메모리를 어떻게 얼마만큼 할당해줄 것인가 그리고 프로세스가 알고 있는 주소를 통해서 실제 메모리에 어떻게 저장하게 할 것인가 즉 할당과 접근 이 두 가지가 운영체제의 메모리 관리 기법의 핵심입니다.
프로세스가 CPU를 통해 실행되기 위해서는 각각의 프로세스에게 메모리 공간이 할당되어야 합니다. 프로세스에게 메모리 공간이 할당된다는 것은 프로세스의 구성 요소인 코드와 데이터가 실제 메모리 공간의 어떤 위치에 저장될지 주소가 결정된다는 것을 의미합니다. 그리고 이러한 과정이 Address Binding입니다. 소스상에서는 함수명이나 변수명을 통해서 심벌의 형태로 주소를 가리키고 있으며 컴파일시 심벌들이 논리주소를 갖게되고 컴파일의 마지막 단계인 Linking과정에서 실제 메모리 주소값을 갖게되어 할당되게 됩니다. 그런데 Execution Time 즉, Runtime 중에 새롭게 메모리 바인딩이 일어날 수도 있습니다. 즉, 프로그램을 실행해서 메모리에 올렸는데 그 프로세스의 메모리 위치가 바뀔 수도 있다는 것입니다.(가상메모리 얘기 메모리 크기가 작다. 활발하게 활동하지 않을떄에는 스케쥴링wait에서 길게 있을 때에는 보조기억 장치에 존재하게 한다. 즉 하드디스크에 내려갔던 가 다시 메모리에 올라올때 변화한 메모리 구성상태에 맞게 프로세스의 메모리 위치를 변경시켜야한다.)
만약에, 프로세스의 위치 정보와 실제 메모리의 주소를 같은 값으로 바인딩하게 된다면 컴파일 타임이나 로드타임에 바인딩이 빠르게 이루어지겠지만 실행 타임에서 스케쥴링에 의해 메모리 주소가 바뀌게 된다면, 프로세스의 어떤 변수와 같은 소스코드의 메모리 주소 조차도 위치가 바뀌어야하고 다시 run상태가 될때 변수의 메모리 주소가 어떤 값인지를 다시 알아야하는 문제가 발생하게 됩니다.
따라서 운영체제는 프로세스가 사용하는 공간의 위치정보를 논리 주소(가상 주소) 공간이라는 것으로 고정시켜 놓고 프로세스의 데이터가 실제 저장되어 있는 위치 주소 값으로 변경시켜주는 서비스를 제공하고 있습니다. 따라서, 실행 타임에 실제 위치 주소가 바뀌더라도 함수나 변수에 해당하는 주소가 변경되지 않고 같은 논리 주소 값으로 접근할 수 있는 장점을 갖게 됩니다. 프로세스의 논리 주소를 실제 메모리의 물리 주소로 변환하는 역할을 MMU 메모리 관리 장치가 하게됩니다.

CPU가 어떤 프로그램을 실행할 때 특정 코드 한줄을 읽으려고 한다. 이 코드를 읽어오는 것 조차도 메모리를 통해 읽어야하는 것이기 때문에 메모리 주소가 필요하다. 하지만 이 CPU가 이해하고 있는 주소는 논리주소로 통용된다. 이 논리 주소는 매번 실행할 때 마다 물리 주소로 바뀌어야되기 때문에 배보다 배꼽이 더 큰 작업이되는 것이고 따라서 MMU라는 하드웨어의 힘을 빌린다.
동적 적재
메모리 관리 기법에 직접적으로 속하지는 않지만 메모리를 절약해서 써야 한다는 목표를 달성하기 위해서 필요한 개념으로 알고 있습니다.
로딩을 고정적으로 static하게 하지 않고 동적으로 한다는 의미입니다. 예를 들어서, 프로그램에는 자주 실행하는 코드가 있고 상황에 따라 다르겠지만 Exception과 같이 자주 사용되지 않거나 아예 사용되지 않을 수도 있는 코드가 있습니다. 이렇게 자주 사용되지 않은 코드는 실행타임에서 필요할 때 로딩을 한다는 의미가 동적 로딩입니다. 이는 운영체제의 특별한 지원이필요 없이 라이브러리를 통해 구현이 가능하다고 알고 있습니다.
동적 연결
링킹은 여러개의 소스코드가 컴파일 되어 재배치 코드 즉 오브젝트코드가 여러개 생겼을 때 이것을 하나로 묶는 링킹 과정이 있어야 최종 실행 파일이 되는 것이고 라이브러리와 같이 미리 만들어져 있는 코드도 내가 만든 코드와 연결이 되어야합니다. 그런데, 여러 프로그램에서 사용되는 printf와 같은 라이브러리는 굳이 중복해서 메모리에 적재하게 되면 메모리 낭비로 이어질 수 있게됩니다. 따라서 라이브러리를 프로그램 내부에 내장하지 않고 printf를 호출하겠다라는 어떤 정보만 담고 있는 Stub코드를 포함해서 컴파일을 완료하고 프로그램이 실행될때 라이브러리를 로딩하거나 이미 다른 프로그램에 의해 로딩되어 있는 라이브러리를 새로운 프로그램에서도 사용할 수 있도록 해주는 것이 동적 연결입니다. 따라서 Shared Library를 사용하여 라이브러리를 여러 프로그램이 공유할 수 있고 메모리의 보호를 해제해야하기 때문에 운영체제의 도움이 필요해집니다.
메모리 관리 기법
시간이 지날수록 프로세스가 요구하는 메모리량이 점점 증가하지만, 여러개의 프로세스를 동시에 메모리에 적재해야하기 때문에 메모리 과닐 서비스가 더욱 중요해지고 있습니다. 메모리 관리의 목적에서 가장 중요한 것은 한정된 크기에 메모리를 여러개의 프로세스에게 효율적으로 할당하는 것입니다. 그리고 이러한 할당 방법에 따라 메모리를 관리하게 되면 프로세스가 메모리의 주소를 직접적으로 참조하는 것이 아니라 논리주소와 물리주소 구분하고 있기 때문에 좀더 빠르게 메모리 주소를 참조할 수 있는 관리 방법도 추가적으로 필요하게됩니다.
1) 스와핑(Swapping)
부족한 메모리 공간을 효율적으로 사용하고자 하는 목적에 부합하는 메모리 관리 기법입니다. 현재 스케일링 되고 있는 프로세스 중에서 CPU에서 실행되고 있지 않은 Ready나 wait상태의 프로세스들을 메모리에 보관하지 않고 보조저장장치에 보관(힙 스택 등등 그대로)하는 방식입니다. 이를 통해 메모리 크기가 작더라도 많은 양의 프로세스들을 스케쥴링을 통해 관리할 수 있게됩니다.

스와핑은 프로세스의 스케줄링 상태에 의존하여 동작하게 된다.

CPU에서 실행을 하고 있다가 Interrupt나 I/O 요청에 의해 ready queue와 waiting queue에 들어가게됩니다.
Interrupt가 걸리게 되면 ready queue에 들어가기 때문에 다른 프로세스들의 작업이 끝나야지 다시 run상태에 진입할 수가 있어서 시간이 오래 걸릴 것을 고려하고 swap out하여 우선 보조저장장치에 저장하는 방식을 사용하게됩니다.
I/O Waiting상태는 마찬가지로 CPU를 사용하고 있지는 않지만 입력에 따라 출력을 기대하고 있는 상황이기 때문에 swap out을 사용하지 않게됩니다. 이렇게 Swapping과정이 이루어지고 해당 프로세스가 다시 메모리 상으로 올라온다면 실행시간 Address Binding이 이루어지게 됩니다.
Swapping방식의 메모리 관리 기법을 사용하는 운영체제에서는 스케쥴러의 디스패처의 동작이 약간달라지게 됩니다. 왜냐하면 CPU에 의해 실행되고 있지 않은 프로세스가 Ready Queue에 있지 않고 Swap Out되어 하드디스크 상에 있기 때문에, 디스패처는 프로세스의 상태를 Ready에서 Run으로 바로 바꿔줄 수 있지 않고 일단 Swap In으로 프로세스를 메모리상에 올리는 과정이 필요합니다. 그런데 Swapping하는 것 자체가 메모리가 부족해서 하는건데 Swap In으로 메모리에 올린다는건 모순입니다. 따라서 Waiting 중이거나 Ready Queue에 있는 다른 프로세스들을 Swap Out을 해주어야합니다.
Swap in Swap Out하는 과정은 초단위로 굉장히 작업 속도가 느린편인데 문맥 교환과 함께 Swapping과정이 사용되게 된다면 굉장히 큰 성능저하로 이어질 수 있다. 따라서 일반적인 스왑 방식은 실제 시스템에 적용하기 어렵다고 알고 있습니다. 따라서 UNIX의 경우에는 메모리의 프로세스가 너무 많아 시스템 부하가 발생할 경우에만 사용하기도 하고 프로세스에서 자주 사용하고 있는 일부만 스와핑하도록 최적화할 수 있습니다.
2) 연속 메모리 할당(Contiguous memory allocation)
메모리 요구량이 서로 다른 프로세스들을 메모리에 적재할 때, 프로세스 전체를 하나의 커다란 공간에 연속적으로 할당하는 방법입니다.
프로세스들을 연속적으로 할당을 하 되, 만약 실행이 끝난 프로세스가 발생한다면 메모리의 일부에 빈 공간이 생기게 됩니다. 이 때 새로운 프로세스가 들어오게 되면, 비어 있는 공간 중에서 할당 될 공간을 선택해야 하는데 이 것이 동적 메모리 할당이며, 세 가지의 방식이 존재합니다.
- 최초 적합(First-Fit) : 프로세스가 요청한 크기에 만족하는 첫 번 째 가용 공간(위에서부터 쭉 읽었을 때 만족하는 크기 첫번 째 공간)
=> 빠르게 찾을 수 있다. 하지만 최선이 아닐 수 있다.(남는 공간이 생길 수 있기고 작은 메모리로 쪼개져서 못써버림)
- 최적 적합(Best-Fit) : 프로세스가 요청한 크기에 만족하는 가용 공간 중에서 가장 작은 것 할당(딱 맞는거)
=> 메모리 낭비를 최소화 할 수 있지만, 최초 적합에 비해 검색 시간이 느리다.
- 최악 적합(Worst-Fit) : 가장 큰 가용 공간을 찾아 할당
=> 분할되어 남는 가용 공간을 써서 활용 가능성이 높지만, 검색 속도도 느리고 메모리 이용 효율도 안좋다
하지만 위 세가지 방법을 사용하더라도 결과적으로는 낭비되는 메모리 공간이 생겨서 메모리 관리의 목적에 부합할 수가 없게됩니다. 이것이 메모리의 단편화 입니다.
외부 단편화는 메모리 할당이 반복됨으로써 사용할 수 없는 작은 크기의 공간이 분산되어 생기는 현상을 의미합니다.
외부 단편화를 해결하는 방법은 페이징과 세그먼테이션이 있습니다.(메모리 압축도 있지만 운영체제의 비용이 많이들어 비효율)
3) 페이징(Paging)
연속 메모리 할당 시에 발생할 수 있는 외부 단편화 문제를 해결할 수 있는 방안 중 하나입니다. 효율적인 메모리 할당과 프로세스의 효율적인 메모리 참조라는 두가지 메모리 관리 측면을 모두 충족하는 기법입니다.

한 프로세스에 대한 데이터들을 한 덩어리 째 연속적으로 저장하는 것이 아니라, 논리 메모리 공간에서 page라고 하는 단위로 나누어 놓고 물리 메모리 공간에서는 page와 동일한 크기의 Frame으로 나누어 놓아서 하나의 Page를 하나의 Frame에 mapping시키는 것이다. 결과적으로 물리 메모리 상에는 연속적으로 저장되지 않고 외부 단편화 문제가 발생하지 않게 됩니다.
하지만 논리 메모리 공간에서는 Page가 연속적으로 저장되기 때문에 내부 단편화는 생길 수 있지만 그 크기가 외부 단편화에 비해서 매우 작기 때문에 크리티컬한 문제라고 판단하지 않습니다.
결국, 논리 메모리 공간의 Page를 물리 메모리 공간의 Frame에 매핑시키기 위해서 Page Table이라고 하는 또다른 메모리 공간을 참조해야 합니다.
d는 오프셋으로, 한 페이지가 주소를 얼마만큼 점거할 수 있는 범위를 나타낸다.

1)CPU가 프로세스(특정 명령어)를 실행하기 위해서 논리 주소를 통해 메모리를 참조할 것이다.
2)논리 주소에서 Page Number를 통해 Page Table(또 하나의 메모리 공간)을 참조할 것이다.
3)그런데 Page Table은 물리 메모리를 참조하는 것과 동일한 시간이 들기 때문에 속도가 매우 느리다 따라서 TLB라고 하는 캐시 메모리(자주 사용하고 있는 명령어들이 들어있겠지?)를 사용한다. 즉, TLB는 전체 Page Number를 참조하고 있는 것은 아니다.
4)만약 찾고자 하는 Page Number가 TLB에 있다면 Frame Number를 통해 물리 주소를 참조할 것(TLB Hit 혹은 Cache Hit)이고 만약 찾고자 하는 Page Number가 TLB에 없다면 메모리에 저장되어 있떤 Page Table의 Frame Number를 통해 물리 주소를 참조(TLB MISS)할 것이다.
5)그래서 만약 TLB MISS가 나면 오히려 TLB가 없었을 때 보다 오래걸림, 왜냐면 TLB에서 검색을 한다음 Page Table에 오기 때문에
6)따라서, 확률에 너무 의존하게 되는 것인데 TLB MISS를 최소화 하기 위해서 여러 알고리즘을 도입하게 된다. 한번 TLB Miss난 Page Table의 Page Number를 TLB에 저장시키되, 이미 TLB가 가득 차있는 경우에는 TLB의 어떤 Page Number를 뺄까? 하는 것 (페이지 교체에서 다루자)
7)프로세스가 문맥 교환이 일어날 때 마다, TLB에 저장된 값들이 계속해서 바뀔 것이다. (Page Table은 프로세스마다 가지고 있음) 그래서 문맥 교환이 자주 일어나면 오버헤드가 발생하게 되기 때문에 TLB는 여러 프로세스들의 Page Number를 저장할 수 있도록 한다. 따라서, TLB는 어떤 프로세스의 page인가를 추가적으로 저장해야 한다 이것을 Address space Identifier라고 한다.
4) 세그먼테이션(Segmentation)
페이징 메모리 관리 기법과 마찬가지로 프로세스의 논리 메모리 공간을 세그먼트라는 작은 단위로 나누어 물리 메모리 공간에 저장하는 방식입니다. 하지만 페이징의 페이지들은 어떤 고정된 크기로 분할이 되어 있지만, 세그먼트는 프로그램의 논리적 단위에 따라서 프로세스의 메모리 공간을 분할하게됩니다. 예를 들어서, Code,heap,Stack,표준 라이브러리와 같은 의미 있는 단위에 따라 세그먼트를 분할하게 됩니다. 페이지테이블과 마찬가지로 세그먼테이션에도 별도의 메모리 공간인 세그먼트 테이블이 존재합니다. 페이지 테이블은 각각의 페이지들의 공간 크기가 동일하게 때문에 해당 Page Number가 어떤 Frame에 저장되면 되는지에 대한 정보가 담고있지만 세그먼트 테이블은 각각의 세그먼트들의 크기가 다르기 때문에 base라는 시작주소와 limit이라는 끝점을 이용해서 크기도 함께 저장해두고 있습니다. limit을 이용하게 되면 해당 세그먼트의 오프셋이 limit보다 큰 경우 위치가 잘못된 것으로 판단해서 trap을 일으키고 작으면 통과시킴으로써 메모리를 보호할 수 있습니다.

가상 메모리(일단 위의 논리 메모리와 개념은 같지만 가상 메모리는 더 좋은 역할을 한다고 생각)
가상 메모리는 메모리를 관리하는 방법의 하나로서, 각 프로그램의 프로세스를 저장할 때, 실제 메모리 주소를 부여하는 것이 아니라 메모리보다 사이즈가 큰 가상의 메모리 주소를 부여하는 것을 의미합니다. 왜냐하면 프로그램의 용량은 나날이 커지고 있고 메모리의 크기는 그에반해 한정적이기 때문에 효율적으로 메모리를 관리하기 위해서는 논리 메모리 공간을 최대한 활용하여 메모리를 관리할 수 있게 됩니다. 이제 프로그램을 실행때에는 CPU가 우선적으로 가상 주소를 참조하고 MMU가 가상 주소를 물리 주소로 변환함으로써 메모리에 존재하는 원하는 데이터를 참조할 수 있게됩니다. 이러한 가상 메모리를 구현하기 위해서는 두 가지의 핵심 기술이 존재합니다.
1) 요구 페이징(페이징 + 스와핑)
페이징과 동일하게 프로세스를 논리 메모리 공간에 페이지 단위로 구분하여 할당하고 MMU를 통해 물리 주소로 변환하여 참조하는 메모리관리 기법입니다. 그런데, 요구 페이징은 모든 프로세스의 모든 페이지들이 메모리에 할당되는 것이 아니라, 일부만 메모리에 할당되고 자주사용되지 않는 데이터들은 보조저장장치의 별도의 공간에 저장(Swap out)하여 동적으로 메모리에 적재(Swap in)하는 방식입니다.


일반적인 스와핑은 프로세스 단위로 스와핑을 하지만 요구 페이징의 페이지 단위로 스와핑을 하기 때문에 스왑에 필요한 시간을 감소하는 역할을 합니다.
일반 페이징과는 다르게 요구 페이징의 페이지 테이블에는 valid(페이지가 메모리에 존재) invalid(디스크에 존재)라는 추가적인 정보를 저장합니다.
페이지 부재(메모리 과할당 중 하나)
Invalid된 페이지는 어떻게 처리되는 것일까?
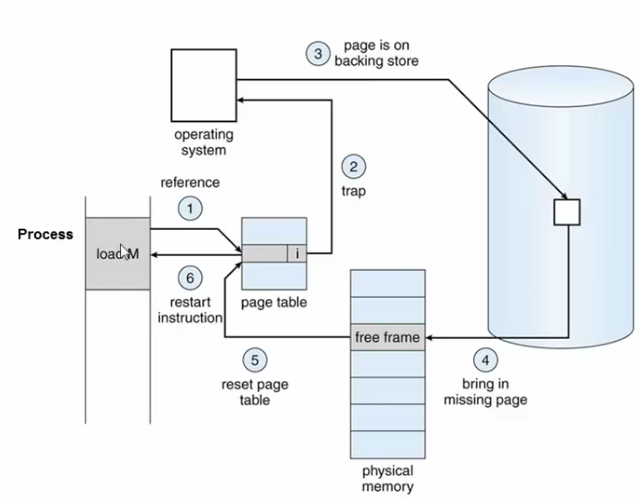
1) 프로세스가 어떤 페이지를 참조하고자 page Table을 검색
2) Page Table의 해당 Page는 현재 Invalid 상태이다. 따라서 Page Fault 즉, Trap이 발생한다.
3) 이를 전달받은 운영체제의 Interrupt Handler에 의해 I/O작업을 시작하게 되고 프로세스는 Waiting상태가 된다.
4) 이제 저장 장치에 있는 페이지를 찾고 물리 메모리에 적재한다.
5) 이제 물리 메모리에 해당 페이지가 존재하므로, Page Table의 해당 페이지는 Valid로 리셋된다.
6) I/O작업이 끝났으므로 해당 프로세스는 스케쥴링에 의해 Running 상태로 변경된다.
이처럼 가상메모리는 메모리의 확장을 통해서 효율적으로 데이터를 할당할 수 있지만 프로세스의 입장에서는 더 복잡한 과정을 겪게됩니다. 기존의 페이징은 TLB를 통해 관리함으로써 이를 해결했지만, 가상 메모리로 관리하는 경우에는 하드디스크까지 거침으로써, I/O시간동안 프로세스의 동작이 멈추는 치명적인 성능 저하가 발생합니다.(물론 지역성 때문에 페이지폴트 확률이 높진 않다)
해결 방법 : 요구 페이징에서의 문제점 자체가 페이지 폴트로 인한 문제이므로, 페이지 폴트를 최소화 하는 것이 가장 근본적인 방안이라고 생각합니다. 일단 페이지 폴트는 지역성의 원리에 의해서 자주 발생하지는 않기 때문에 페이지 폴트의 확률을 더 최소화 할 수 있는 페이지 교체 알고리즘이 필요시되게 됩니다. ( 좋은 페이지 교체 알고리즘은 페이지 사용 패턴을 분석함으로써 자주 사용되는 페이지와 자주 사용되지 않은 페이지를 구분하고 교체하는 것 : 메모리에 올라와있는 페이지 중 가장 사용량이 적은 것을 Swap Out)
메모리 과할당(Over Allocating)
멀티 프로세싱의 목적은 사용자에게 눈속임을 함으로써, 여러 프로그램이 마치 동시에 동작되게끔 보이게 하는 것입니다. 그런데, 간혹 사용자에게 들키는 상황이 발생하게 되는데
1. 프로세스 실행 도중 페이지 폴트 발생
2. 페이지 폴트를 발생시킨 페이지의 위치를 디스크에서 찾는 상황
3. 메모리의 빈 프레임에 Swap In을 해야 하는데, 메모리가 꽉 차있는 상황이 있습니다.
따라서, 이러한 문제를 없애기 위해서는 빈 프레임을 확보할 수 있어야만 합니다.
1. 메모리에 올라와 있는 한 프로세스를 종료시켜 빈 프레임을 얻는 방법이 있습니다.
2. 프로세스 하나를 Swap Out하고, 이 공간을 빈 프레임으로 사용하는 것입니다.(즉, 멀티 프로세싱의 정도를 낮춤)
3. 프로세스가 아니라 페이지들을 스와핑 해서 빈 프레임을 확보함.
하지만, 1번처럼 프로세스를 종료 시켜버림으로써 사용자에게 들켜버리는 메모리 관리는 있어선 안되기 때문에 페이지를 교체하는 방식으로 이루어져야 합니다.
페이지 교체
페이지 교체 알고리즘의 목표는 페이지 폴트를 최소화 하는 것입니다. 페이지를 교체할 때 어떤것을 교체해야지 이 후에 페이지 폴트가 적게 발생할 것인가?(캐시, 버퍼와 같은 비슷한 문제에서도 사용되게된다.)
요구 페이징을 통해 자주 사용하는 페이지만 메모리에 올리고, 자주 사용되지 않은 페이지는 보조저장장치에 스왑 공간에 저장하지만 결국에는 메모리는 가득 차기 때문에 참조하려는 페이지를 Swap In할 수가 없게 됩니다. 따라서, 사용량이 적은 페이지는 Swap Out하고 필요한 페이지를 Swap In해주어야 합니다. 이때, out되는 페이지를 victim Page라고 하는데 기왕이면 사용량이 적고, 수정이 되지 않는 페이지를 Out시켜주어야 합니다. 이와 같이 메모리 과할당을 해결하기 위한 방안이 페이지 교체 알고리즘입니다.
페이지 교체 알고리즘을 평가 하기 위해서는 알고리즘을 직접 운영체제에 넣어서 컴파일 하는건 힘들고, 시뮬레이션 해보는 방법이 있다.
참조하고자 하는 페이지들의 번호만을 모아놓은 데이터를 가지고 시뮬레이션을 수행해야 합니다.
reference string : 결함이 발생한 페이지 번호
1) FIFO(FIRST IN FIRST OUT) 페이지 교체 알고리즘
가장 간단한 알고리즘이다. 특히 초기화 코드에서 가장 적절한 방법이다.
초기화 코드는 처음 프로세스가 실행될때 최초 초기화를 시키는 역할만 하고 다른 역할은 하지 않으므로(수정이 적게 일어남) 메모리에서 내려와도 괜찮다. 즉, FIFO 알고리즘을 통해 일단 메모리에 올라오고 가장 먼저 내보내기에 좋다.

먼저 Swap In한 페이지가 먼저 Swap Out되는 페이지 교체 알고리즘입니다.
1) 7번이 요구됐다 -> 메모리에 없기 때문에 0번 프레임에 Swap In한다
2) 0번이 요구됐다 -> 메모리에 없기 대문에 1번 프레임에 Swap In한다
3) 1번이 요구됐다 -> 메모리에 없기 때문에 2번 프레임에 Swap In한다
4) 2번이 요구됐다 -> 메모리에 없어서 Swap In해야하는데 꽉찼다. 따라서 First In했떤 7을 빼고 2를 넣는다
5) 0번이 요구 됐다 -> 이미 있다
6) 3번이 요구 됐다 -> 메모리에 없어서 Swap In해야하는데 꽉찼다. 2는 가장 마지막에 들어온 놈이기 때문에 0을 빼고 3을 넣는다.
벨러디의 모순 : 프레임의 개수가 많아지더라도 페이지 부재율이 높아지는 현상이 발생할 수 있다.
2) OPT(Optimal Page Replacement)최적 페이지 교체 알고리즘
앞으로 가장 오랜시간 사용되지 않을 확률이 높은 페이지를 가장 우선적으로 Swap Out시키는 알고리즘
= 다른 모든 알고리즘보다 페이지 폴트율이 낮으면서 벨러디의 모순이 발생하지 않는 페이지 교체 알고리즘
하지만 실질적으로 페이지가 앞으로 잘 사용되지 않을 것(미래의 정보 = 기상청 같이)이라는 명확한 보장이 없기 때문에 수행하기 어려운 알고리즘이다. 따라서, 제안된 알고리즘의 성능 비교의 목적으로 사용된다.

1) 7번이 요구됐다 -> 메모리에 없기 때문에 0번 프레임에 Swap In한다
2) 0번이 요구됐다 -> 메모리에 없기 대문에 1번 프레임에 Swap In한다
3) 1번이 요구됐다 -> 메모리에 없기 때문에 2번 프레임에 Swap In한다
4) 2번이 요구됐다 -> 메모리에 없기 때문에 Swap In해야하는데 꽉찼다. 기존의 7,0,1을 보면 7이 가장 나중에 참조될 것이기 때문에 7을 Out하고 그 자리에 2를 In한다.
3) LRU (Latest-Recently-Used) 페이지 교체
최근에 사용하지 않았다면, 나중에도 사용하지 않을 것이라는 아이디어에서 도출된 알고리즘입니다. OPT의 경우에는 미래 데이터를 통해서 예측을 하지만 LRU의 경우에는 과거 데이터를 기반으로 했기 때문에 실질적으로 사용이 가능한 알고리즘입니다. OPT보다는 페이지 폴트가 실제로 더 발생할 수 있지만, 실현 가능하다는 측면에서 가장 좋은 방법 중 하나로 채택되고 있습니다.

1) 7번이 요구됐다 -> 메모리에 없기 때문에 0번 프레임에 Swap In한다
2) 0번이 요구됐다 -> 메모리에 없기 대문에 1번 프레임에 Swap In한다
3) 1번이 요구됐다 -> 메모리에 없기 때문에 2번 프레임에 Swap In한다
4) 2번이 요구됏따 -> 메모리에 없기 때문에 Swap In해야하는데 꽉찼다. 기존의 7,0,1을 보면 7이 가장 과거에 참조되었었기 때문에(= 최근에 사용이 안됐기 때문에) 7자리에 2를 Swap In한다.
4) Counting 기반의 페이지 교체 (잘 사용하지 않음)
- LFU : 참조 횟수가 가장 적은 페이지를 교체하는 알고리즘(참조 횟수가 적기 때문에 Swap Out을 시킨다는 일차원적 생각)
- MFU : 참조 횟수가 가장 많은 페이지를 교체하는 알고리즘(참조 횟수가 적은 페이지가 최근에 사용한 것이라서, 앞으로 사용될 가능성이 높기 때문에 참조 횟수가 가장 많은 페이지는 앞으로 사용될 가능성이 적어 교체한다)
구현에 상당히 많은 비용이 들고, LRU를 대체할만한 알고리즘이 아니기 때문에 실제로는 사용율이 적은 페이지교체 알고리즘으로 기억하고 있습니다.
교체 방식(Local - Global)
멀티 프로세싱을 하면 메모리 상에 다양한 프로세스들의 페이지들이 올라오게 됩니다. 이 때, Global교체 방식과 Local교체 방식을 생각할 수 있는데, Global은 메모리 상의 모든 프로세스들의 페이지를 고려해서 교체하는 방식이고 Local은 자신의 페이지들만 고려해서 교체하는 방식입니다. 실제로는 Global 교체 방식이 더 효율적이라고 알고 있습니다.
쓰레싱
만약, 메모리 상에 이미 활발히 사용되고 있는 페이지들만으로 이루어져 있다면 이 후에 페이지 교체가 발생했을 때, 또 다시 얼마 지나지 않아 바로 페이지 교체가 수행될 것입니다.(활발한 놈이 Out됐으니 금방 In돼겠지) 이렇게 발생할 수 있는 과도한 페이징 작업을 쓰레싱이라고 합니다. 이러한 현상을 방지하기 위해서는 각 프로세스가 필요로 하는 최소한의 프레임 갯수를 보장해 주는 방법이 있습니다.
캐시 메모리
주기억장치에 저장된 내용의 일부를 임시로 저장해두는 기억장치
CPU와 주기억장치의 속도 차이로 성능 저하를 방지하기 위한 방법
CPU가 이미 봤던걸 다시 재접근할 때, 메모리 참조 및 인출 과정에 대한 비용을 줄이기 위해 캐시에 저장해둔 데이터를 활용한다
캐시는 플리플롭 소자로 구성되어 SRAM으로 되어있어서 DRAM보다 빠른 장점을 지녔다.
- CPU와 기억장치의 상호작용
CPU에서 주소를 전달 → 캐시 기억장치에 명령이 존재하는지 확인
- (존재) Hit
해당 명령어를 CPU로 전송 → 완료
- (비존재) Miss
명령어를 갖고 주기억장치로 접근 → 해당 명령어를 가진 데이터 인출 → 해당 명령어 데이터를 캐시에 저장 → 해당 명령어를 CPU로 전송 → 완료
이처럼 캐시를 잘 활용한다면 비용을 많이 줄일 수 있다.
따라서 CPU가 어떤 데이터를 원할지 어느정도 예측할 수 있어야 한다.
(캐시에 많이 활용되는 쓸모 있는 정보가 들어있어야 성능이 높아짐)
적중률을 극대화시키기 위해 사용되는 것이 바로 지역성의 원리
- 지역성
기억 장치 내의 정보를 균일하게 액세스 하는 것이 아니라 한 순간에 특정부분을 집중적으로 참조하는 특성
지역성의 종류는 시간과 공간으로 나누어진다.
시간 지역성 : 최근에 참조된 주소의 내용은 곧 다음에도 참조되는 특성
공간 지역성 : 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
- 캐싱 라인
빈번하게 사용되는 데이터들을 캐시에 저장했더라도, 내가 필요한 데이터를 캐시에서 찾을 때 모든 데이터를 순회하는 것은 시간 낭비다.
즉, 캐시에 목적 데이터가 저장되어있을 때 바로 접근하여 출력할 수 있어야 캐시 활용이 의미있어진다.
따라서 캐시에 데이터를 저장할 시, 자료구조를 활용해 묶어서 저장하는데 이를 캐싱 라인이라고 부른다.
즉, 캐시에 저장하는 데이터에 데이터의 메모리 주소를 함께 저장하면서 빠르게 원하는 정보를 찾을 수 있다. (set이나 map 등을 활용)
파일이란?
파일은 프로그램 또는 데이터, 자료와 같은 정보들의 집합을 말합니다. 이러한 정보를 저장할 수 있는 메모리 공간은 디스크에 할당되어 있으며 디스크에 존재하는 여러 파일들은 각자 고유한 이름을 가짐으로써 식별할 수 있습니다.
디렉토리란?
파일의 메타데이터(파일 이름, 타입, 위치, 사이즈 등) 중 일부를 보관하고 있는 특수한 파일이다. 이 디렉토리는 다양한 구조로 존재할 수 있으며 구조에 따라 파일에 더 손쉽게 접근할 수 있게된다.
파일의 구조
파일은 바이트의 연속적인 연결이라고 정의되어 있으며 UNIX의 경우에는 8바이트의 단순한 집합으로 인식하여 이 내부구조를 운영체제가 해석하지 않습니다. 시스템 차원의 지원이 없는 대신 응용 프로그램들의 각자의 프로그램에 사용되는 파일 구조에 대해 해석과 운용을 책임지고 있습니다. 단 프로그램을 로딩하고 수행할 수 있는 실행 파일은 운영체제가 읽을 수 있도록 지원해야 합니다.
파일과 디스크
파일은 정보를 저장할 수 있는 공간인 디스크에 할당되어 있고 이름을 통해 식별할 수 있습니다. 이러한 디스크는 비휘발성 저장장치로써 고정된 블록단위로 데이터를 저장하게 됩니다. 모든 디스크의 입력과 출력은 섹터(물리적 레코드)단위로 이뤄집니다. 대부분 한 블록은 512바이트이고 연속적인 바이트로 구성된 파일이 512바이트로 나뉘어져 디스크 곳곳에 저장되게 됩니다. 하지만 디스크는 구조적으로 바이트 단위의 자료를 읽을 수 없기 때문에 파일 시스템을 통해서 파일과 디스크 블록간의 연결작업을 해주어야 합니다.
파일시스템이란?
파일 시스템은 디스크에 파일을 효율적으로 저장하며, 저장되어 있는 파일에 접근할 수 있는 기법을 제공하는 모듈입니다.
파일 시스템의 특징
1. 사용자 영역이 아니라 커널 영역에서 동작합니다.
2. 파일 시스템은 실제적인 데이터를 저장하는 파일과 파일들을 계층적으로 연결하는 디렉토리로 구성됩니다.
3. 디스크 공간을 세분화 관리하기 위해 파티션으로 나눌 수 있는 각 파티션별로 서로 다른 파일 시스템을 가질 수 있습니다.
파일 시스템의 목적
1. 파일을 효율적으로 저장하고 관리하는 것
2. 파일에 접근하기 위한 서비스를 제공하는 것
파일접근 방법 (파일에 접근하여 데이터를 읽는 방법)
1)순차 접근
테이프의 모델을 기반으로한 방법으로, 읽기 쓰기 시스템콜이 발생한 경우에 포인트를 맨 앞으로 보내서 순서대로 읽어나가는 방식입니다. 만약 데이터 a,b,c가 있을 때 a에서 c를 읽기 위해서 반드시 b를 거쳐야 하는 방식입니다.
2)직접 접근
순차 접근과는 다르게 순서의 제약이 없이 특정 데이터에 곧바로 접근할 수 있는 방식으로 데이터 a,b,c에서 포인터가 a에 잡혀있을 때, c를 읽기 위해 b를 거치지 않아도 곧바로 c에 임의 접근이 가능합니다. 대규모의 정보를 접근할 때 유용하기 때문에 데이터베이스에 활용되어 집니다.
디렉터리 구조
1) 1단계 디렉토리
디렉토리에 저장되어 있는 하나 식별자가 하나의 파일을 연결하고 있는 1:1 매핑 구조로써, 매우 간단한 구조를 가지고 있지만 파일에 개수가 많아질수록 디렉토리의 메타데이터 개수도 많아지기 때문에 파일 시스템에 파일이 너무 많아진다면 비효율적이게 된다.
2) 2단계 디렉토리
마스터 파일 디렉토리와 유저 파일 디렉토리 두 단계로 나누어 파일에 접근하는 구조로써, 마스터 파일 디렉토리를 사용자의 이름이나 계정번호로 식별하고 있으며 유저파일 디렉토리는 말그대로 자신만의 사용자 파일 디렉토리가 됩니다.
3) 트리 구조 디렉토리
2단계 디렉토리의 확장된 다단계의 트리 구조입니다. 루트 디렉토리를 시작으로 하위 디렉토리들이 비순환 방식으로 연결되어 있어 찾고자 하는 파일을 log시간 안에 빠르게 찾을 수 있게됩니다.
4) 그래프 구조 디렉토리
연결은 되어있지만, 방향으로 봤을때는 순환하지 않고 있는 그래프 구조의 디렉토리입니다. 예를 들어서, 특정 파일의 가상본을 만들었다면 서로 다른 디렉토리에서도 해당 파일에 링크를 연결할 수 있게됩니다.
'Computer Science' 카테고리의 다른 글
| 정리[NetWork] (0) | 2021.04.13 |
|---|---|
| 정리[Database] (0) | 2021.04.08 |