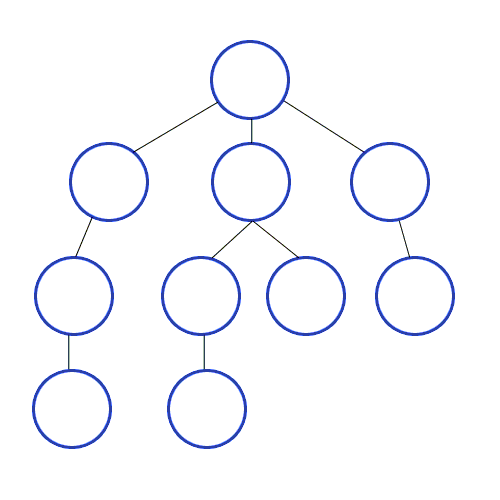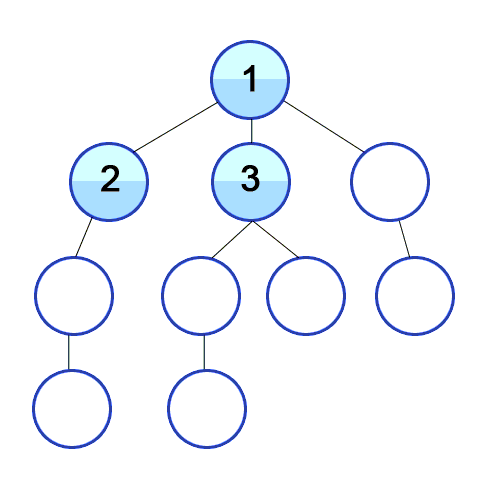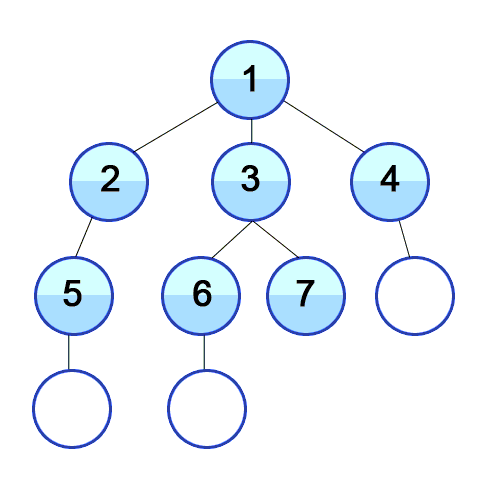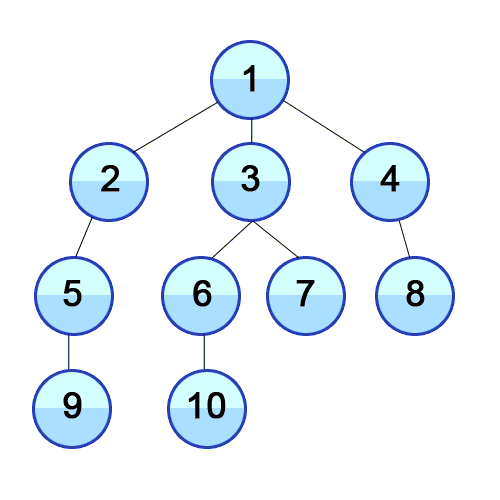
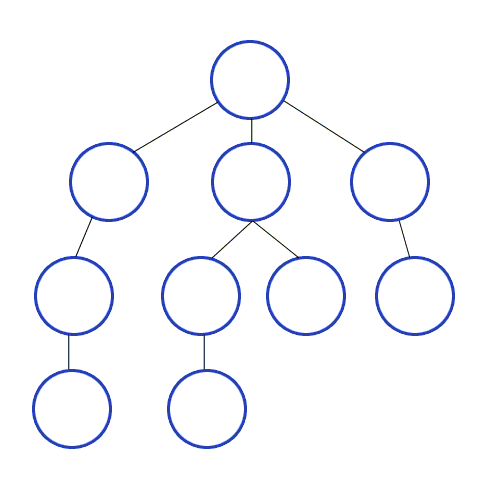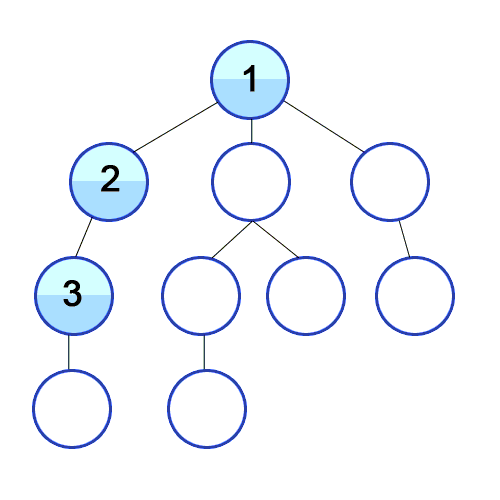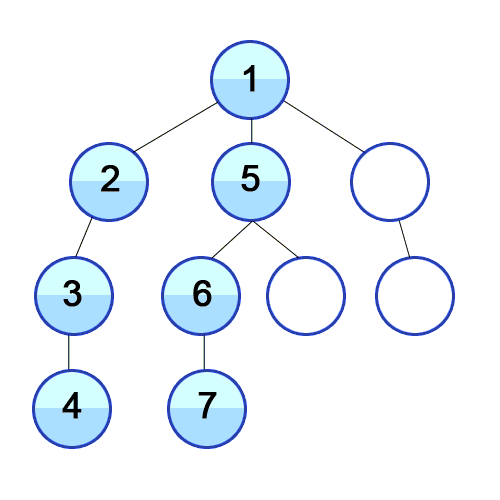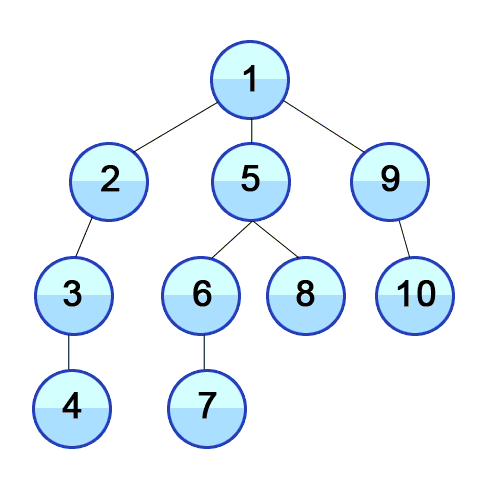
개념 하나의 정점으로부터 시작하여 인접한 노드를 모두 방문하고 차례대로 모든 정점들을 한 번씩 방문하는 알고리즘 과정 장점 장점으로는, 출발노드에서 목표노드까지의 최단 길이 경로를 보장합니다. (물론 모든 간선의 가중치가 동일할 경우입니다.) 단점 단점으로는, 최악의 경우 모든 노드에 대한 정보를 위한 공간을 요구한다는 것입니다. 따라서 최대 저장공간을 크게 잡아야 합니다. 또한 목표노드가 깊은 단계에 있을 경우 오랜 시간이 소요됩니다. 시간복잡도 인접 행렬 : O(V^2) 인접 리스트 : O(V+E) 소스코드 - 인접리스트 public class BreadthFirstSearch_Source : MonoBehaviour { void Start() { int n = 5; // 정점의 개수 int m = ..